

Apache Spark Thrift Server in Yeedu enables users to run SQL workloads using standard JDBC/ODBC tools while leveraging Spark’s distributed processing capabilities. This document provides a complete, step-by-step guide to setting up and using Yeedu Thrift, covering prerequisites, cluster configuration, and linking external clients through a Spark JDBC connection.
Yeedu Thrift is a managed Spark Thrift Server provided by the Yeedu platform. It allows users to interact with Spark using SQL without submitting Spark jobs manually, bringing the power of Apache Spark SQL Thrift to familiar analytics workflows.
Using Yeedu Thrift, users can:
This approach removes the operational overhead typically associated with running and managing individual Spark jobs or legacy Hive Thrift Servers.
Before running Thrift jobs in Yeedu, ensure the following requirements are met to support correct Spark Thrift server configuration:
To run Thrift jobs successfully, complete the following steps:
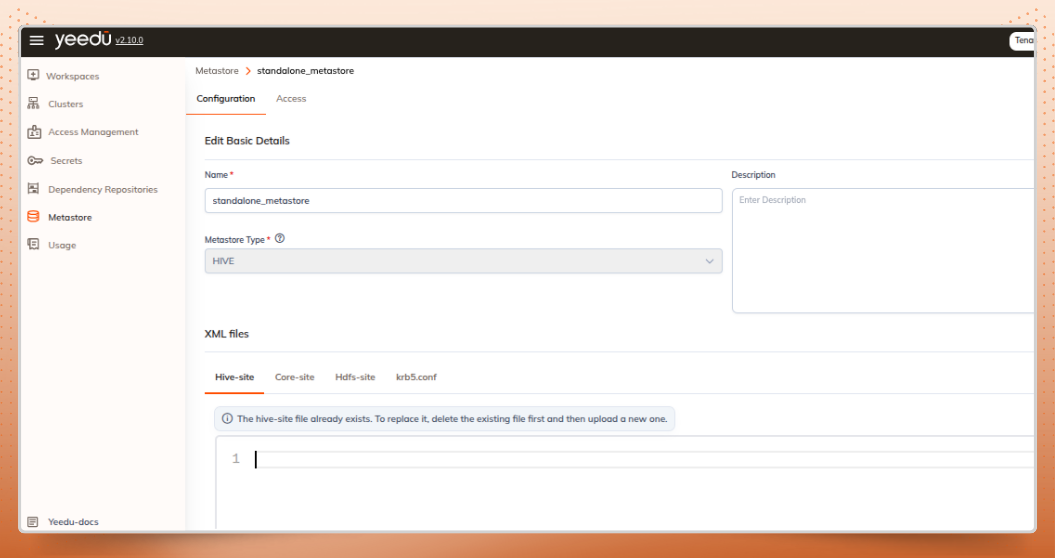
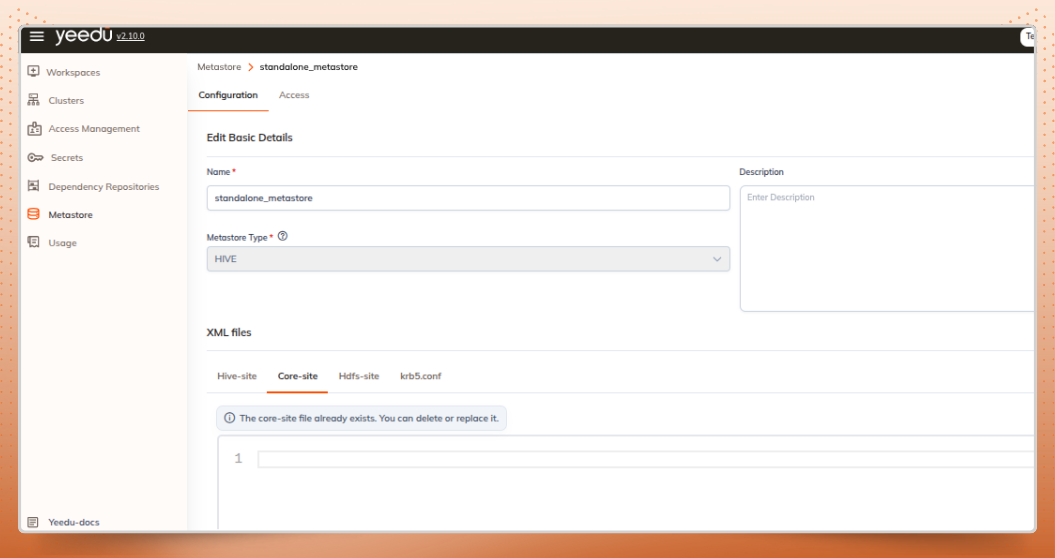
Yeedu Thrift relies on a Hive Metastore to store and manage table and schema metadata used by Apache Spark SQL workloads.
standalone_metastore
This standalone metastore will be used by the Spark Thrift Server to manage metadata centrally.
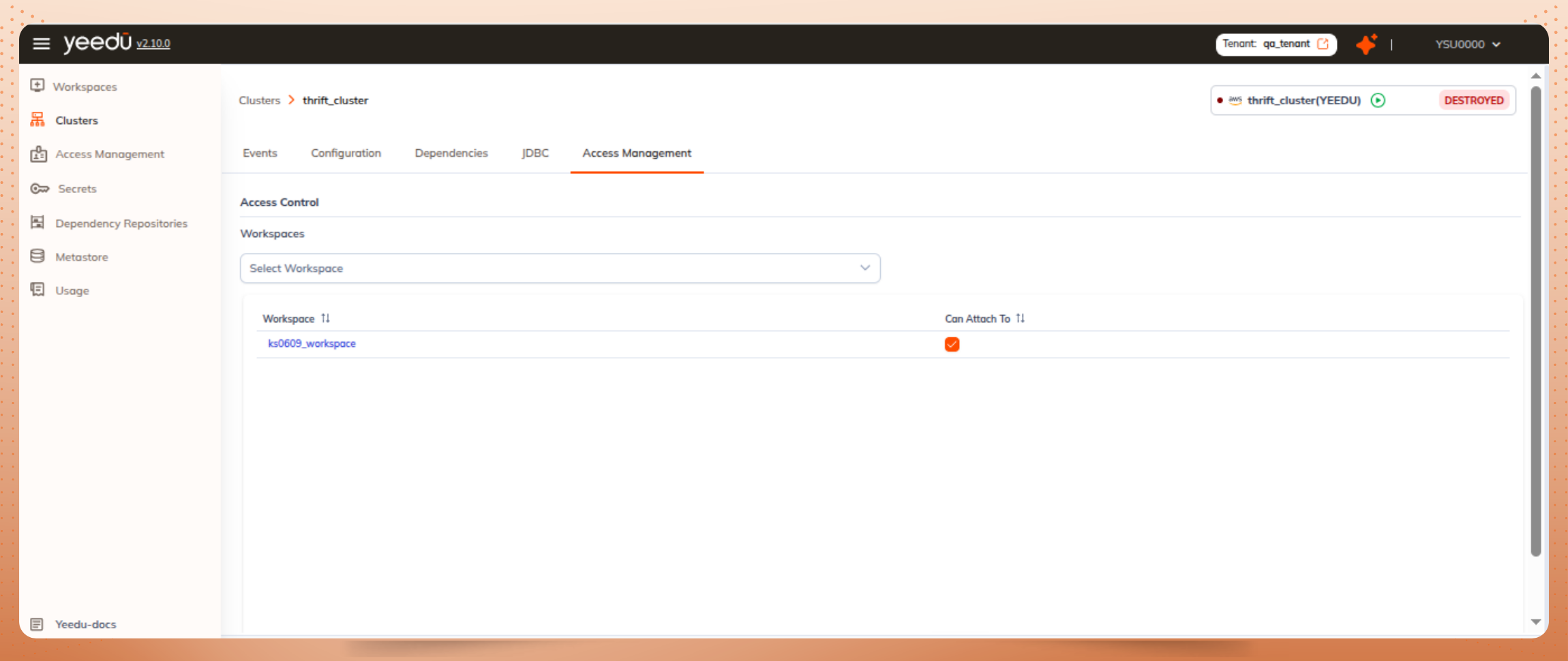
From the Yeedu UI, create a new cluster with the following settings:
Once created, the cluster will be capable of running workloads on Spark Thrift Server.
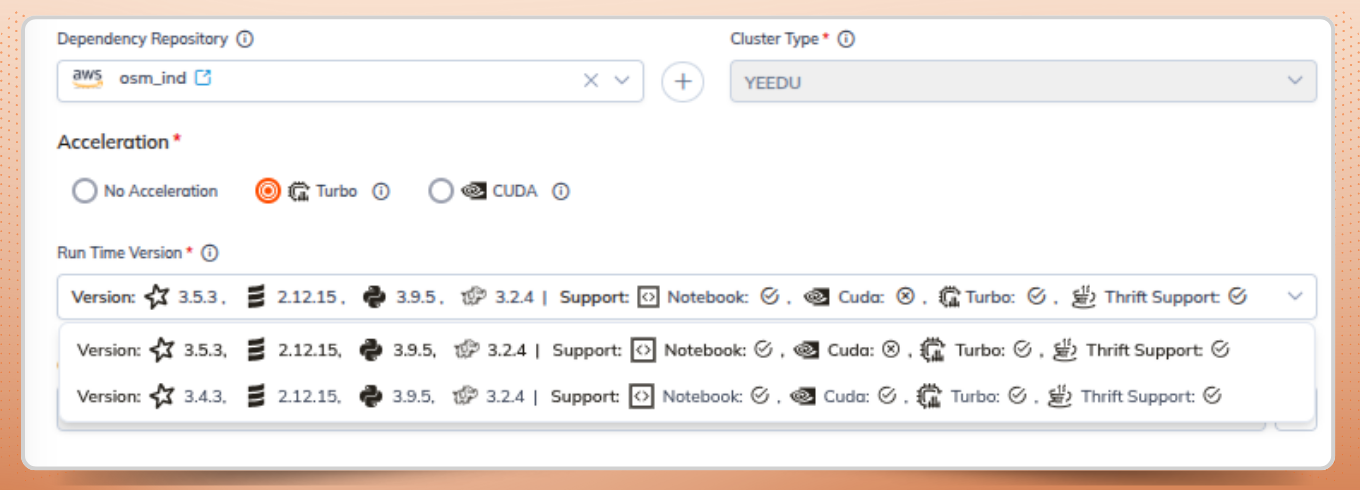
Add the Maven dependency to the cluster configuration:
Example : org.apache.hadoop:hadoop-aws:3.2.4
This package is required for accessing S3-compatible object storagew hen queries are executed through Apache Spark SQL Thrift.
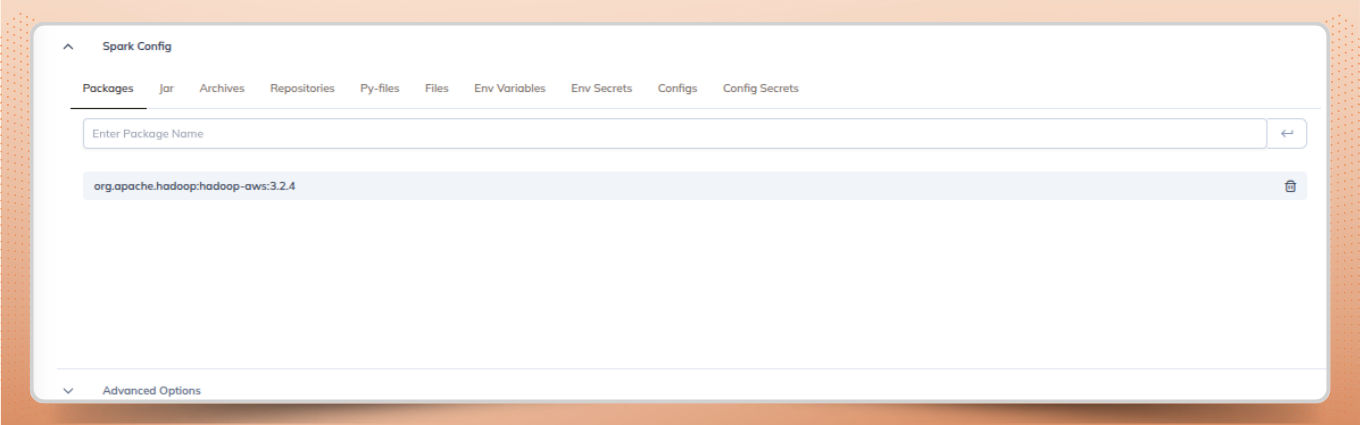
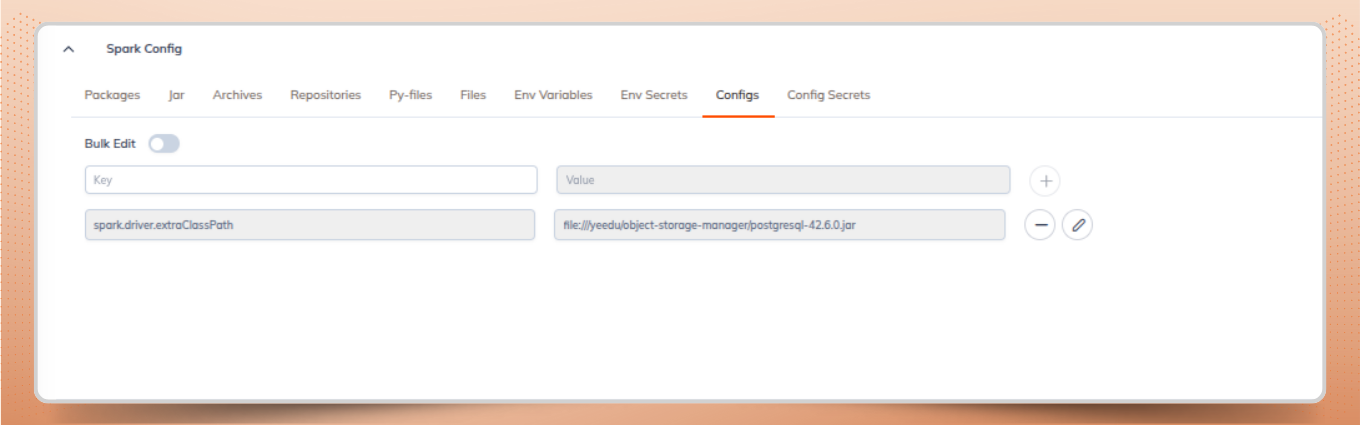
Add the Spark configuration to the cluster to complete the Spark Thrift Server configuration.
This ensures that the PostgreSQL JDBC driver is available to the Spark driver for Hive Metastore connectivity.
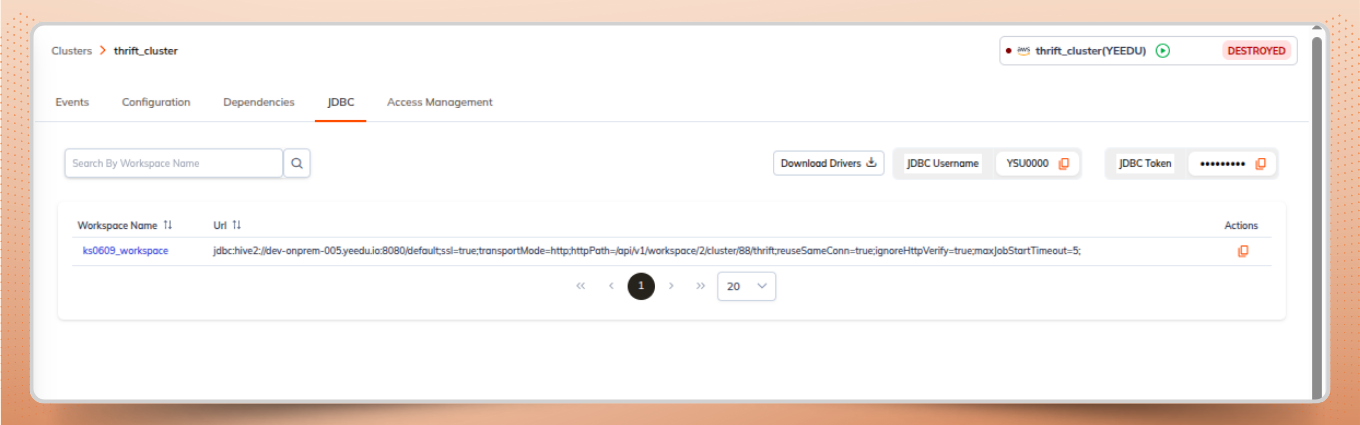
After the cluster is up and running, Yeedu automatically provisions a Spark Thrift Server.
The following connection details are displayed for establishing a Spark JDBC connection:
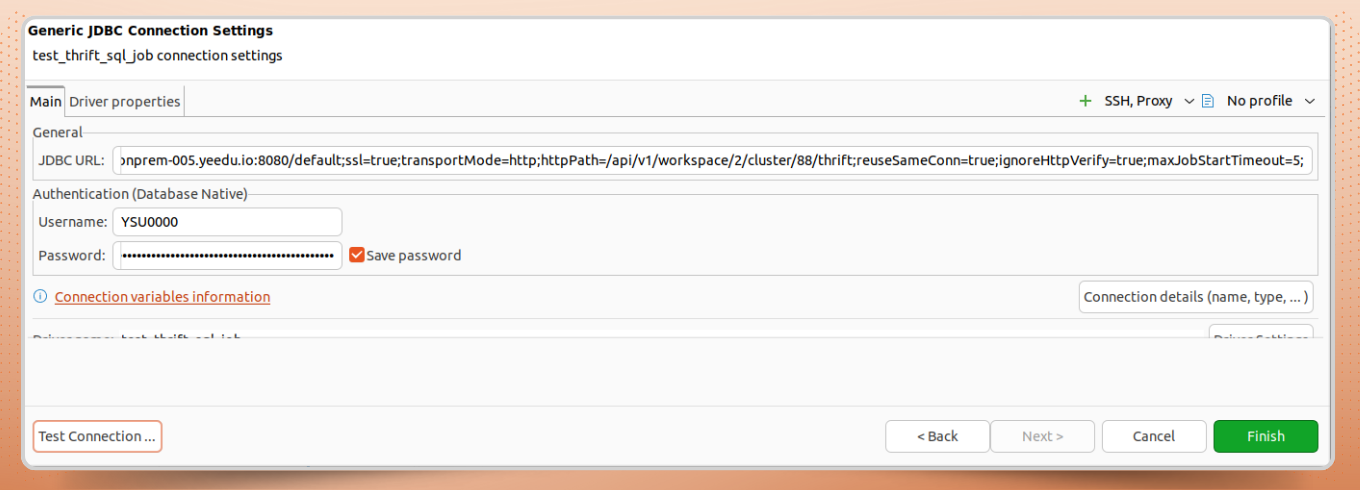
Yeedu Thrift can be accessed using any JDBC-compatible SQL client that supports Apache Spark SQL Thrift.
Example: Connecting with DBeaver
Once connected, you can execute Spark SQL queries directly from the client via the managed Spark Thrift Server.
After the setup is done:
Yeedu Thrift simplifies running SQL workloads on Spark by combining a managed Spark Thrift Server with workspace-level security and centralized metadata management. With a standalone Hive Metastore, minimal Spark Thrift Server configuration, and built-in JDBC support, teams can efficiently query data using familiar SQL tools while leveraging Apache Spark SQL Thrift for distributed execution. This approach enables both interactive analytics and production-grade SQL workloads with minimal operational overhead.



