
If your Spark jobs still line up single file behind a busy cluster, you’re paying for idle time. Modern teams need two things at once:
Yeedu does both: cluster-level concurrency controls to multiplex jobs, plus Turbo, a C++ vectorized engine for CPU-bound speedups without changing your Spark code. Recent coverage cites up to 4–10× performance gains and ~60% cost reductions, making this a practical path for both Spark performance and cost optimization.
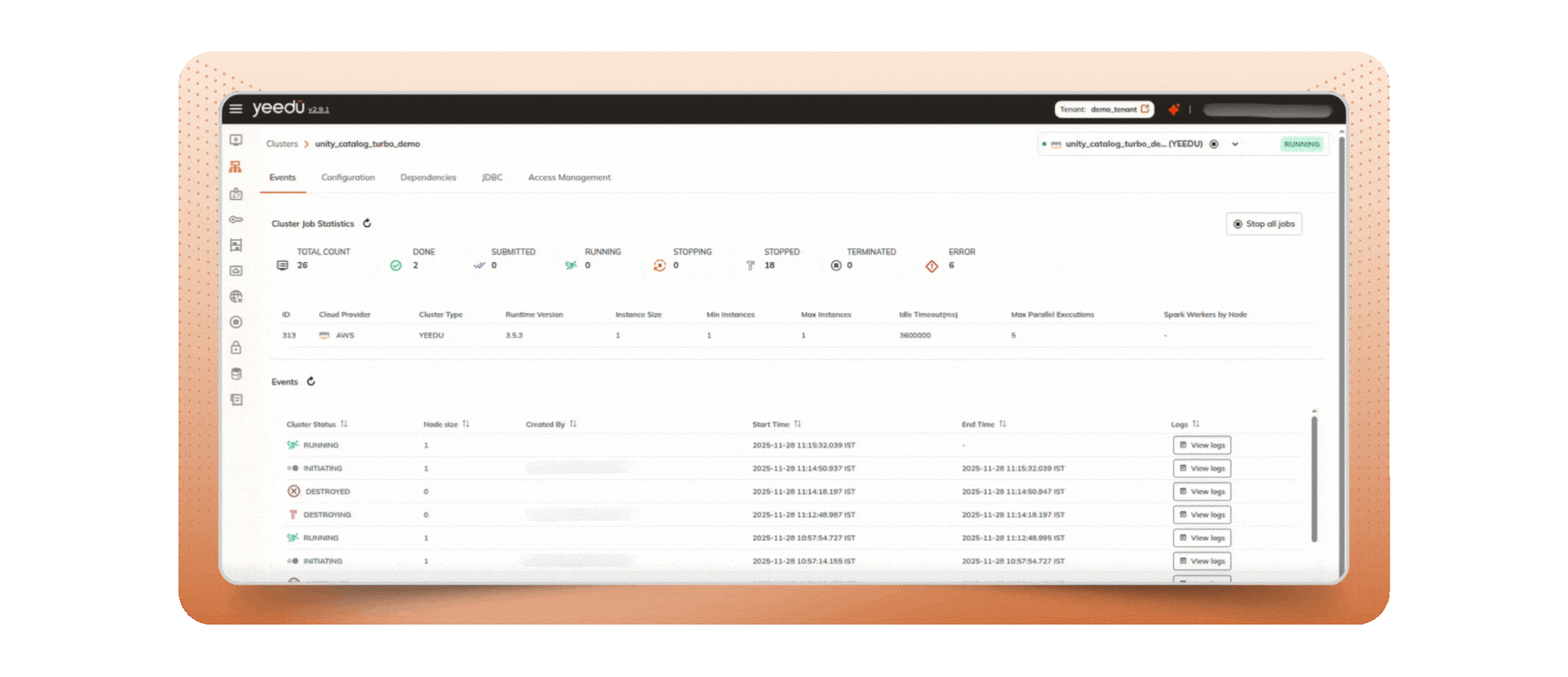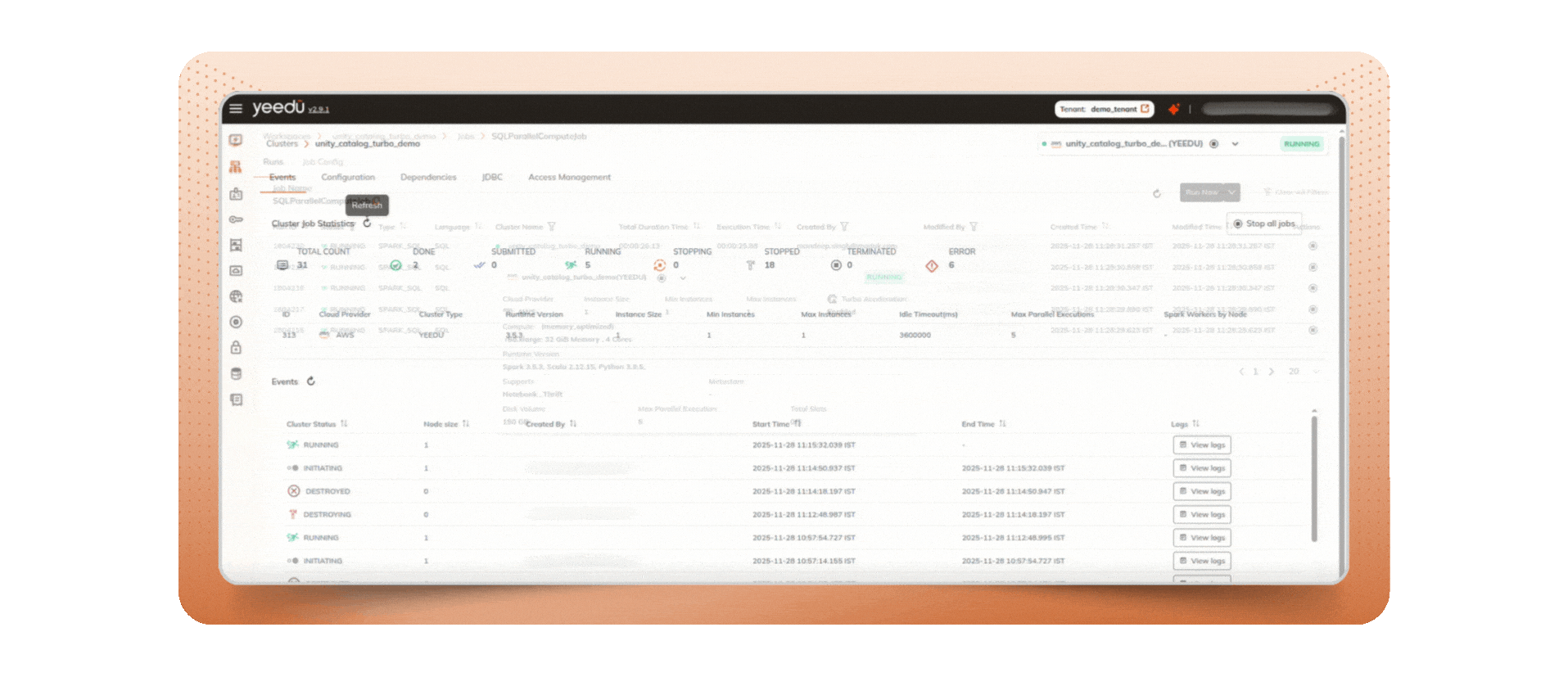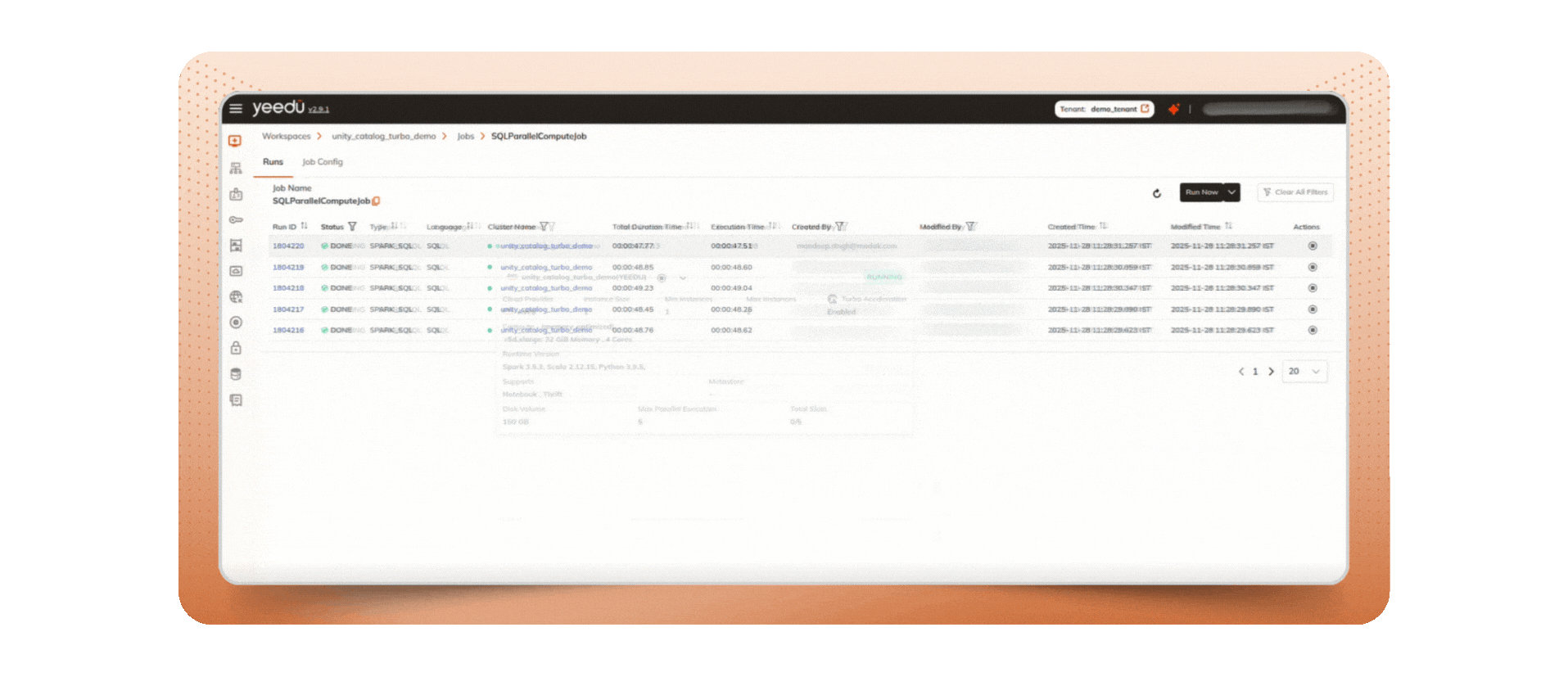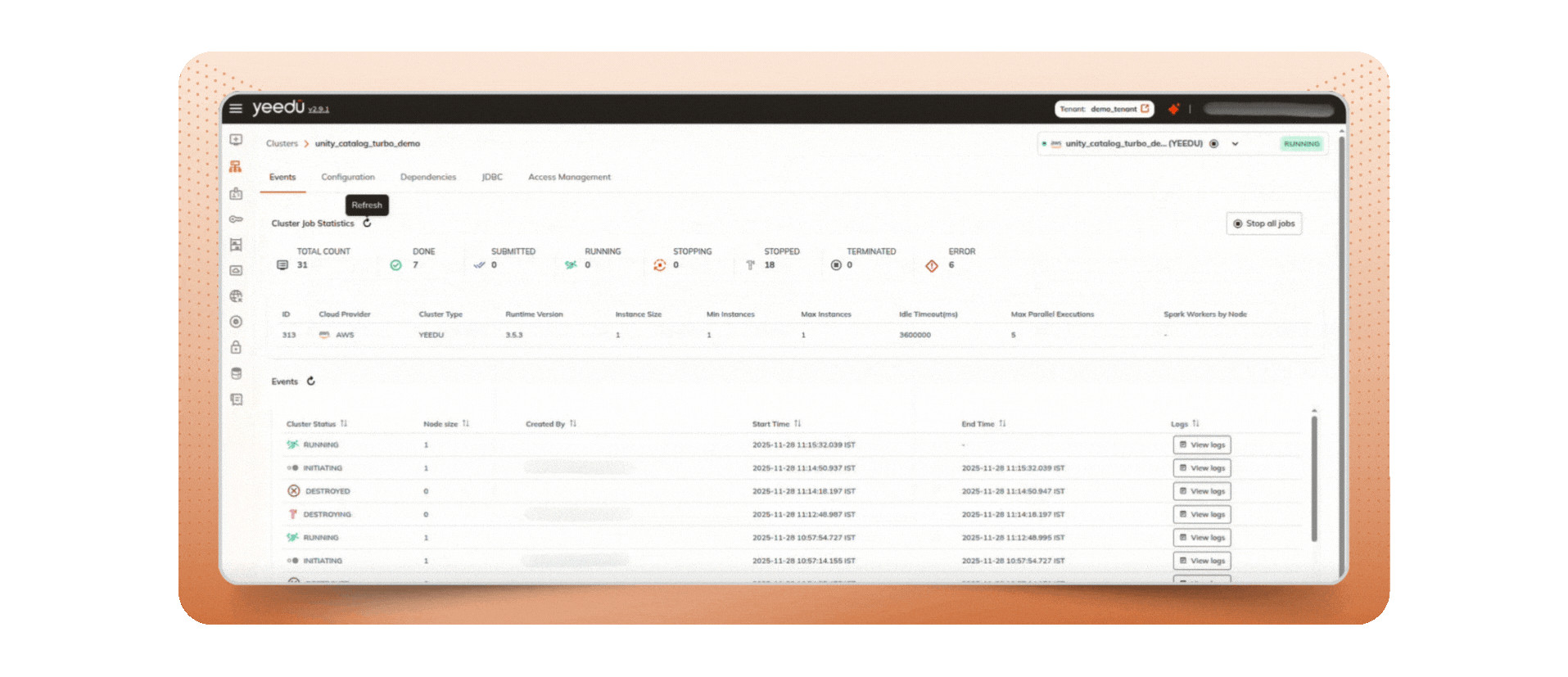
Multiplexing is the ability to submit multiple Spark jobs and run them in parallel on one cluster (multiple drivers), instead of forcing every workload to wait behind a single long runner. In Yeedu, clusters surface a “Max parallel execution” control so you can set how many jobs run concurrently and avoid head-of-line blocking a clean operational pattern for teams that need to submit multiple Spark jobs without creating excess clusters.
Yeedu’s control plane manages clusters across AWS, GCP, and Azure, so you can point many jobs to the same target where the data and price/performance make sense without juggling three different UIs.
Docs: Architecture | Yeedu Documentation
TL;DR: Multiplexing converts a single queue into multiple lanes. Short, time-sensitive jobs no longer idle behind “whales,” and your cores spend more time doing useful work. This is the simplest, most reliable form of Spark job optimization because it reduces pipeline idle time without adding engineering overhead.
Multiplexing lifts throughput; Turbo shortens per-job runtime. Turbo uses vectorized operators, SIMD, and cache-aware processing hardware-friendly techniques that reduce CPU cycles per row so CPU-bound Spark/SQL workloads finish dramatically faster, with zero code changes.
This has a direct impact on Spark shuffle optimization scenarios where CPU bottlenecks stall the pipeline: vectorized operators reduce shuffle-side processing time without requiring developer rewrites.
Benchmark: Accelerating Chemical Similarity with Yeedu Turbo
Further reading
If you’re still shipping Spark jobs through a single lane, you’re leaving performance and money on the table. Multiplexing gives you more lanes; a vectorized engine makes every lane faster. With Yeedu’s cluster-level Max parallel execution, multi-cloud control plane, and Airflow/UI/CLI monitoring, you can submit multiple Spark jobs, wait less, and pay less while achieving meaningful Spark performance optimization without rewriting your pipelines.
.avif)


