

Enterprises are grappling with skyrocketing data processing costs while demanding faster analytics. The challenge isn’t just about running Apache Spark workloads it’s about achieving Spark performance optimization at scale without breaking the bank. Enter Yeedu, a platform that’s rethinking how Spark workloads are orchestrated and executed.
For CTOs and data engineering teams, Yeedu promises to cut data processing expenses by an average of 60% while improving performance by up to 10x, all without requiring code changes. But how does the architecture actually deliver these bold claims in real-world Spark workload optimization scenarios?
Yeedu is a comprehensive Software-as-a-Service (SaaS) platform designed to provide organizations with a cost-optimized infrastructure for Apache Spark workloads across AWS, Microsoft Azure, and Google Cloud Platform. At its core, yeedu is purpose-built to address Spark cost optimization challenges that arise from inefficient execution and underutilized resources.
What sets Yeedu apart is its architectural foundation, which is deeply aligned with modern spark architecture in big data environments.
The architecture comprises three core components: the Yeedu Control Plane, Yeedu Compute, and a UI/CLI. The Control Plane manages all backend services, serving as the platform’s backbone and providing a centralized hub for creating and managing jobs and notebooks.
Yeedu takes advantage of dedicated virtual machine architecture to deploy nodes on separate virtual machines, allowing for more scalable and robust deployment with the ability to horizontally scale, which is an essential prerequisite for sustained Spark performance optimization in elastic cloud environments.
At the heart of Yeedu’s performance gains lies the Turbo Engine a re-architected execution layer that fundamentally reimagines how Spark processes data. Built from the ground up in C++ , Yeedu’s Turbo engine unlocks 4-10x faster job run times compared to standard Spark, directly addressing the long-standing bottlenecks in Spark performance optimization.
The Turbo Engine leverages vectorized query processing with SIMD (Single Instruction, Multiple Data) instructions. Instead of processing data row-by-row like traditional systems, Turbo accelerates CPU-bound workloads using vectorized execution paths, enabling Spark performance optimization at the processor level.
Modern CPUs contain vector registers capable of processing multiple data values simultaneously. While standard Spark processes one value at a time in a loop, Turbo processes 8, 16, or even 32 values with a single instruction. By optimizing execution and optimization for modern CPUs with SIMD capabilities, the Turbo engine brings down the time for execution of data workloads dramatically. The result? Faster execution means lower consumption of cloud resources and significant gains in Spark cost optimization.
Beyond raw processing speed, Turbo’s smart scheduling dynamically packs more jobs per CPU cycle, improving overall cluster utilization and delivering 2–4x higher efficiency. Where traditional Spark often leaves CPUs underutilized, Turbo maximizes compute efficiency through intelligent execution planning which is an overlooked aspect of Spark workload optimization.
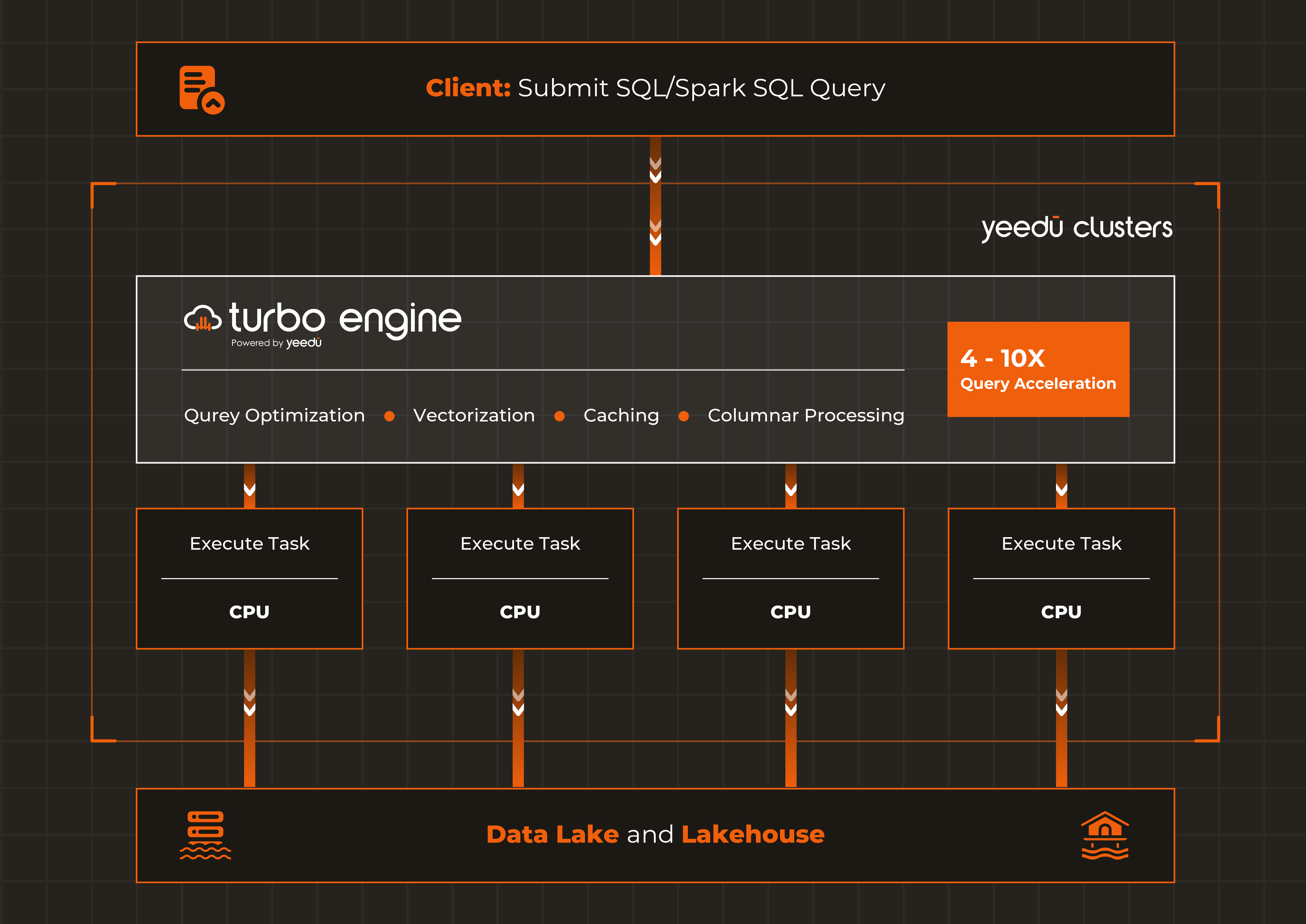
Perhaps most importantly, the Turbo Engine accelerates Spark with zero impact on your codebase. Your existing PySpark or Scala jobs execute faster with no refactoring, delivering immediate ROI with no development effort. This is particularly valuable for organizations pursuing Spark cost optimization without embarking on risky migration or rewrite efforts.
Beyond the Turbo Engine, Yeedu combines a re-architected Spark execution layer with intelligent automation to detect inefficient queries, skewed joins, and shuffle-heavy operations. The platform surfaces actionable recommendations that effectively automate parts of Spark performance optimization traditionally handled through manual tuning.
For data engineers, this means you can migrate PySpark or Scala jobs “as-is” to Yeedu and immediately benefit from systematic Spark workload optimization no rewriting required.
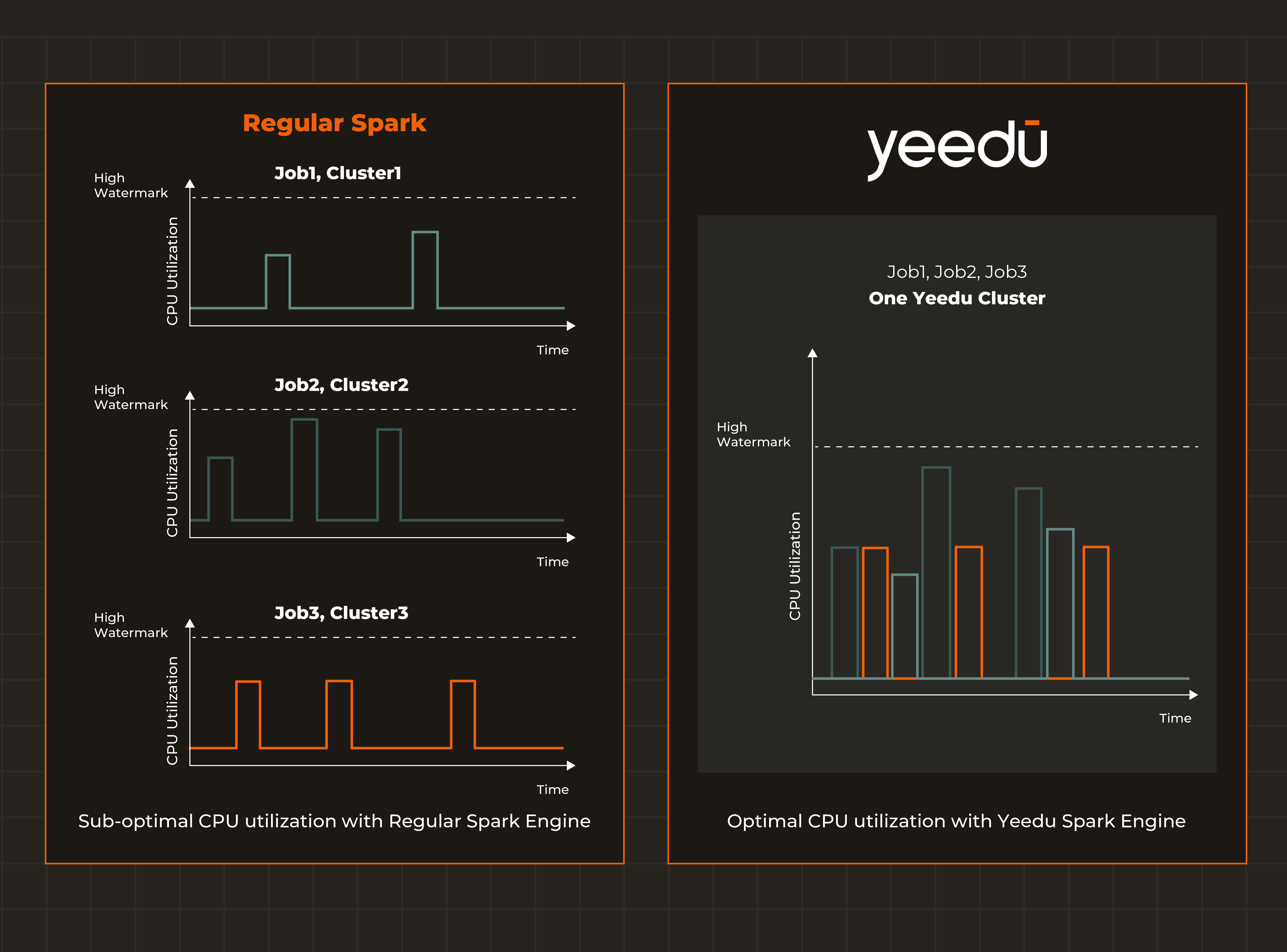
Traditional Spark deployments suffer from a fundamental limitation: static clusters waste resources during off-peak hours, while undersized clusters cause create performance bottlenecks during peak loads.
Yeedu addresses this through intelligent Spark autoscaling, allowing compute clusters to scale up and down based on real-time workload metrics. With auto-scale, auto-start, and auto-stop capabilities, Yeedu ensures resources closely match demand at all times.
This aproach to Spark autoscaling is proactive rather than reactive. Organizations can schedule to stop and start their Spark clusters automatically or trigger scaling based on conditions, ensuring consistent Spark cost optimization by paying only for resources when they are actually needed.
The impact is significant: no more paying for idle clusters running 24/7. Resources spin up when jobs arrive and spin down when work completes, dramatically reducing wasted compute spend.
One of the most persistent challenges in enterprise Spark environments is understanding where costs originate. Effective Spark cost optimization begins with granular visibility, and Yeedu makes it straightforward to track compute usage by job, user, and business context.
The platform provides detailed billing breakdowns that help teams identify inefficiencies and make informed optimization decisions capabilities often sought by organizations struggling with Databricks cost optimization but lacking actionable insight into workload-level spend.
Beyond cost metrics, Yeedu integrates job-specific Spark UI endpoints and Assistant X, enabling engineers to inspect real-time execution metrics, Spark events, and performance bottlenecks directly from job runs. This depth of observability allows teams to pinpoint why certain workloads are expensive an advantage frequently missing in traditional Databricks cost optimization efforts.
Yeedu is designed for enterprise scale and governance. The platform supports multi-tenancy, fine-grained access control, single sign-on, and compliance with stringent regulatory requirements. It also provides comprehensive cluster monitoring with real-time visibility into CPU, memory, and network utilization critical for sustaining long-term Spark performance optimization.
For data science teams, Yeedu notebooks offer features like real-time co-authoring across various languages, seamless version control, and integrated data visualization capabilities, providing an interactive development environment similar to Jupyter notebooks.
Yeedu represents a fundamental rethinking of how Spark workloads should be executed. By combining a C++-based vectorized query engine, intelligent scheduling, VM-based architecture, and comprehensive auto-scaling, Yeedu delivers measurable results:
For organizations struggling with rising data platform costs or evaluating alternatives while struggling with Cloudera or Databricks cost optimization, Yeedu offers a compelling value proposition proven cost savings, dramatic performance improvements, and enterprise-grade features, all while keeping your existing Spark investments intact.
.png)
