

Modern data teams want flexibility and performance without breaking what already works. Many organizations rely on Databricks to power their analytical workloads. However, when it’s time to modernize infrastructure, reduce cost, or adopt an open, multi-cloud platform, migration often feels complex. Code rewrites, catalog rebuilds, and permission mismatches can turn what should be an upgrade into a long and risky project.
Yeedu changes that experience. It enables you to move existing Databricks workloads to Yeedu using a no code data migration flow intentionally built to simplify Databricks notebooks and jobs migration, while directly connecting to your Databricks Unity Catalog setup, preserving your Spark logic, and accelerating workloads using its high-performance Turbo Engine. This approach drastically reduces the friction typically associated with migrating Databricks notebooks and jobs into new environments.
Many Databricks users depend on the Photon Engine for faster Spark SQL and DataFrame execution. Yeedu delivers the same vectorized acceleration with its Turbo Engine, designed for both compatibility and performance.
In practice, teams running CPU-bound analytics see 4–10× faster runtimes on Yeedu compared to unoptimized Spark engines. The Turbo Engine works transparently with your existing code, ensuring the same performance acceleration you expect from Photon and often better efficiency on modern hardware. This makes Yeedu a compelling option for Spark workload performance optimization without any code changes.
Key takeaways
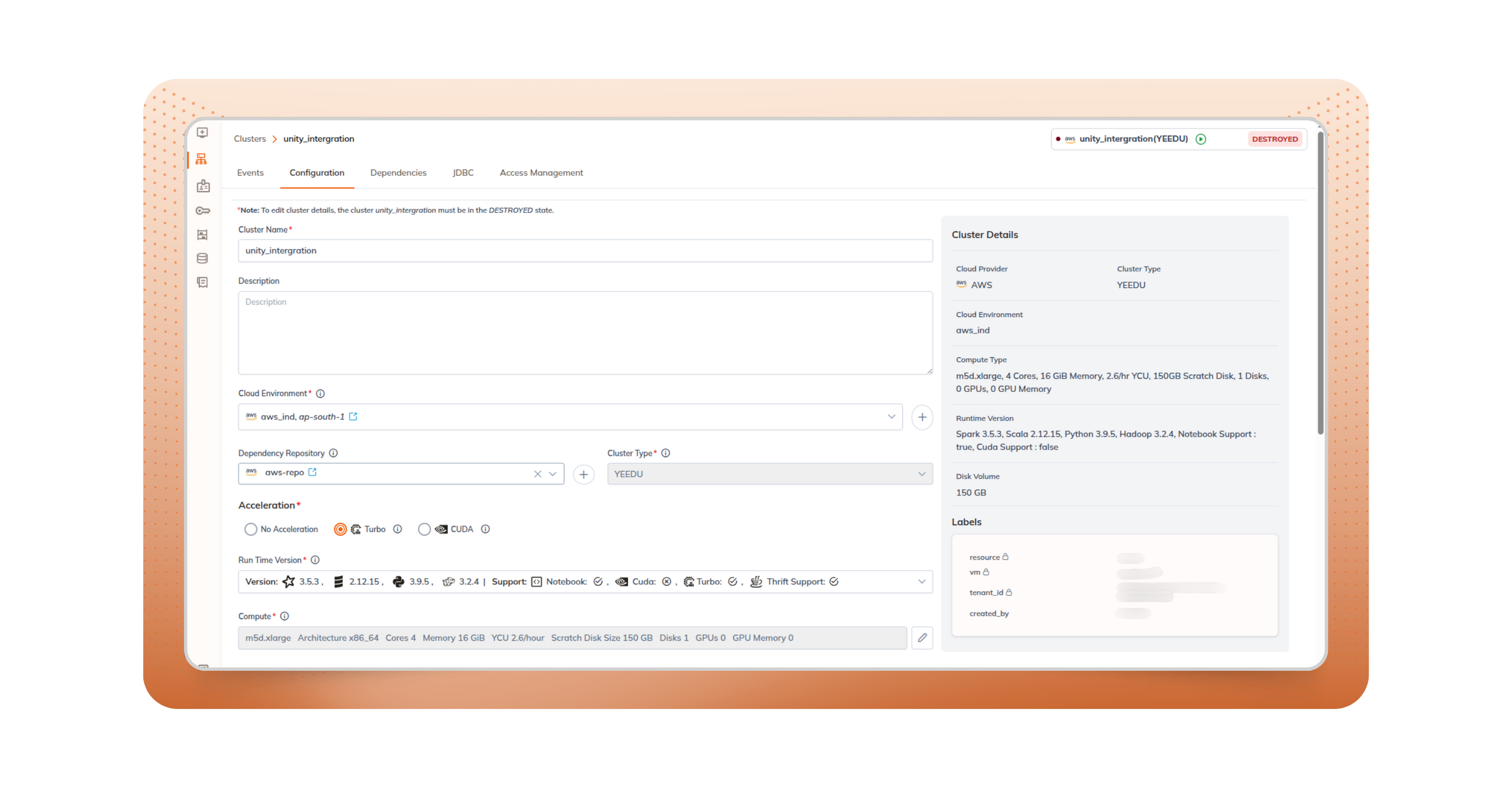
Yeedu eliminates the need for disruptive rewrites. Your Spark transformations, joins, window functions, and Structured Streaming logic continue to run exactly as before making Databricks notebooks and jobs migration smooth, predictable, and fully compatible with your existing logic. The platform is designed for code and operational continuity. You retain all your existing data flows and gain consistent execution across clouds, all enabled by Yeedu’s built-in capabilities as a Databricks migration tool.
Yeedu also supports advanced Databricks functionality:
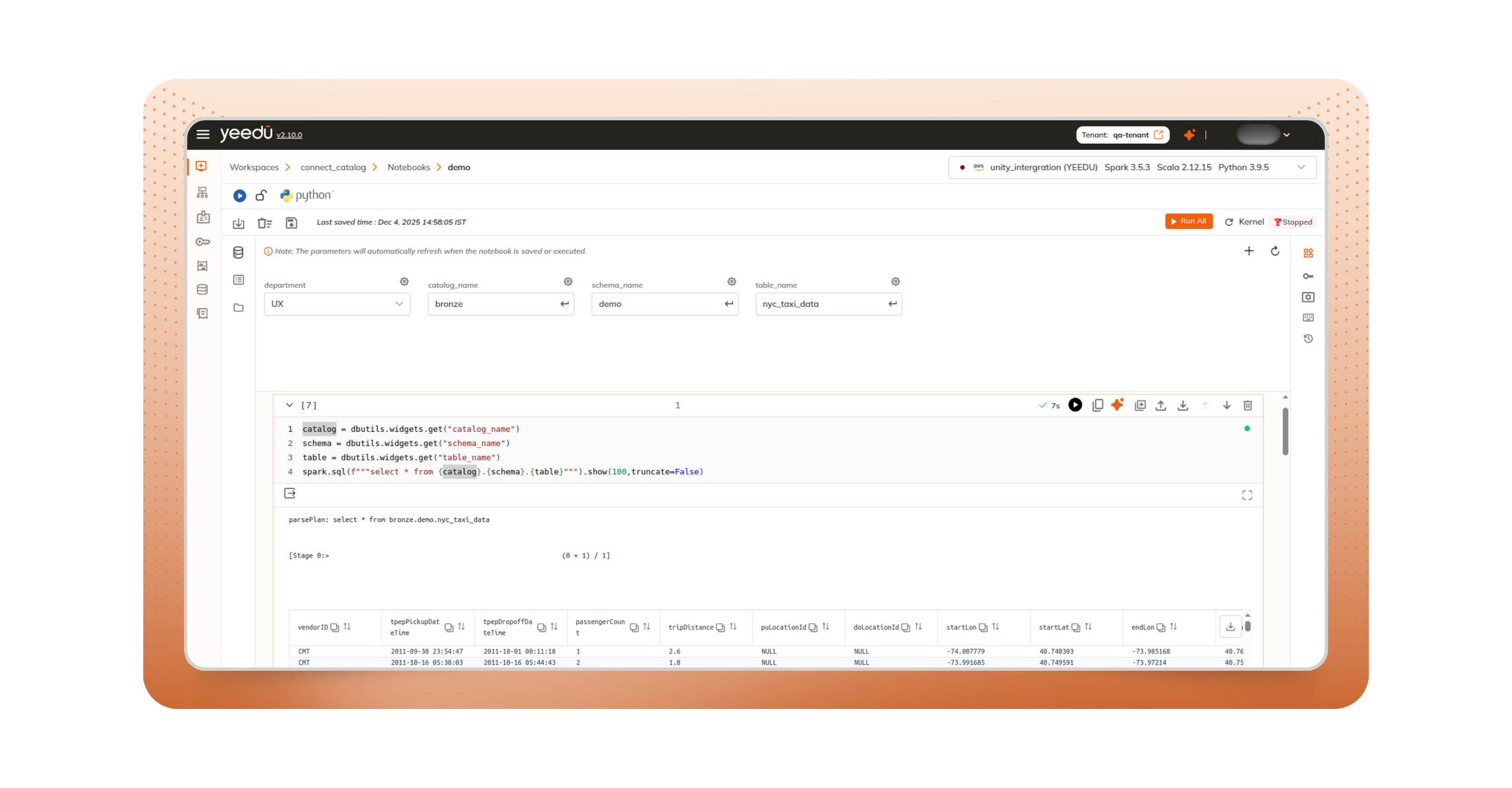
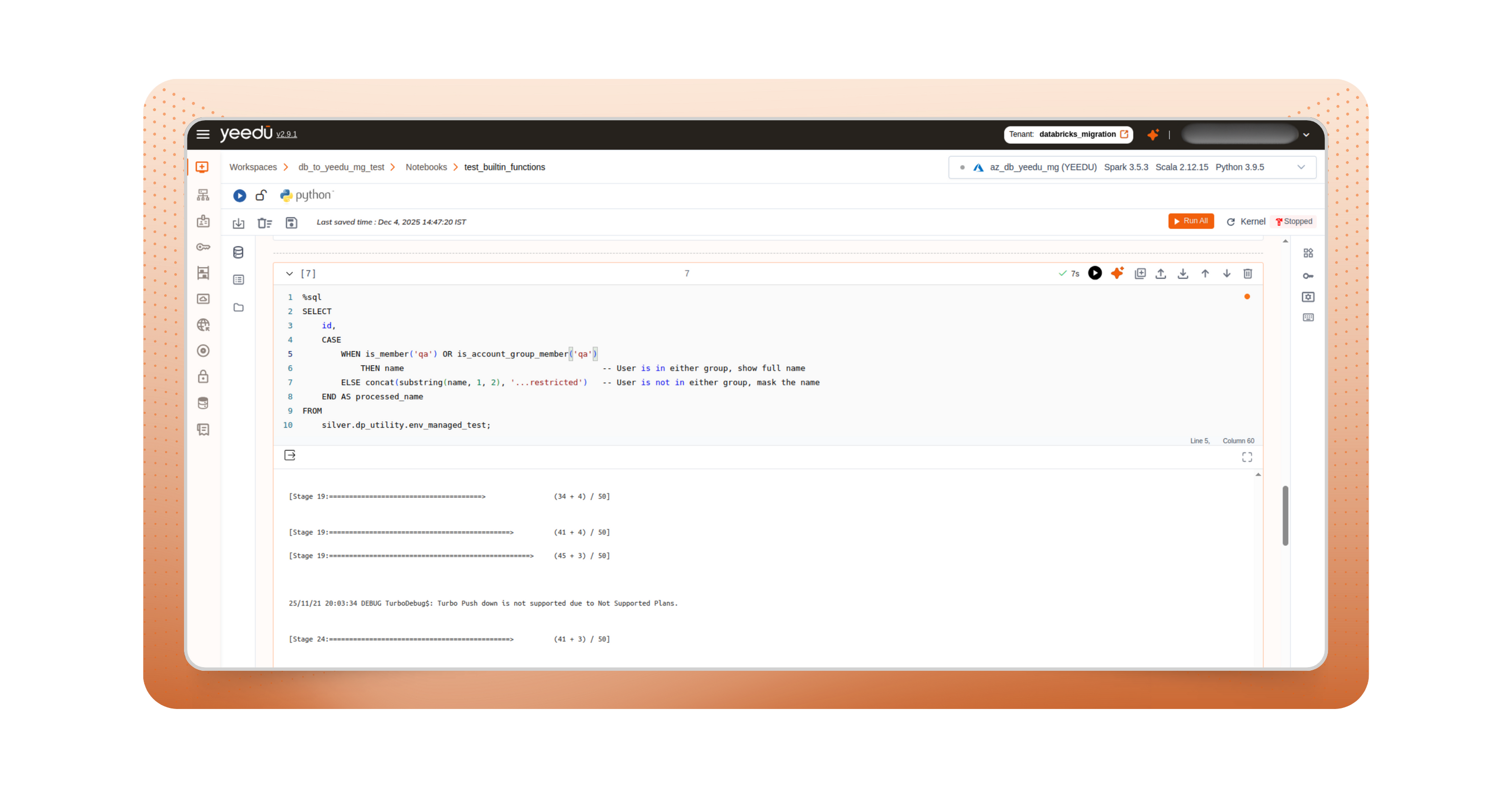
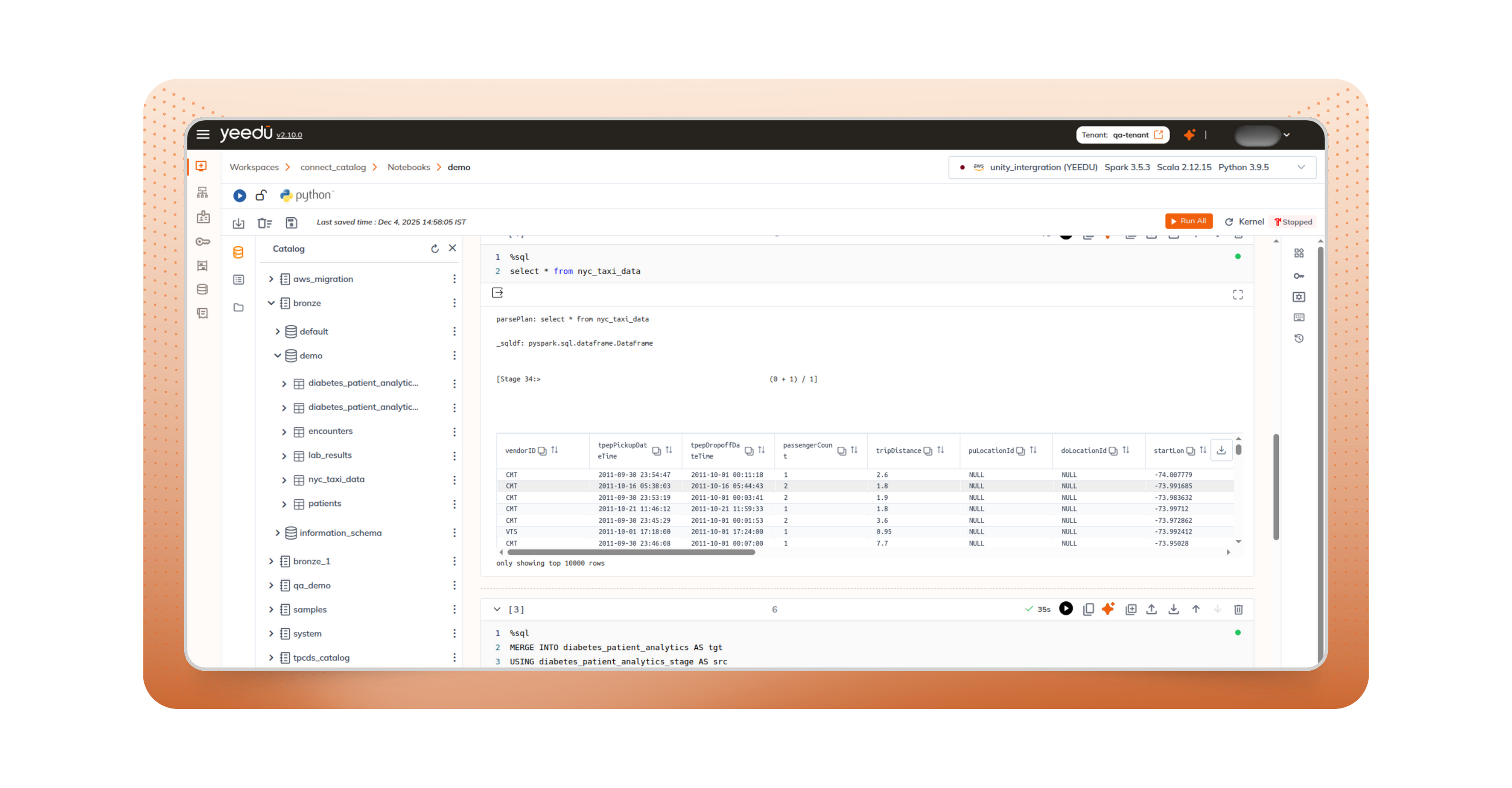
One of the most time-consuming aspects of migration is rebuilding catalogs and permissions. With Yeedu, that step disappears. Yeedu directly connects to your existing Databricks Unity Catalog setup.
Your tables, views, and schemas stay where they are, and your access controls continue as defined. Yeedu respects your existing governance setup rather than copying or replacing it.
Benefits
Yeedu doesn’t just support Airflow. It migrates your Databricks Workflows into Airflow DAGs for you. During migration, Yeedu analyzes each workflow and automatically generates an equivalent DAG that preserves what matters to you dependencies, retries, SLAs, schedules, and conditional logic.
This created a ready-to-run Airflow representation managed by Yeedu, bringing modern Airflow workflow orchestration to your Spark and notebook pipelines.
Once migrated, you operate everything “the Airflow way.” The Yeedu Airflow Operator submits and monitors Spark jobs or notebooks directly from your DAGs. Because your orchestration is now expressed as code, it is version controlled, testable, and repeatable across environments.
In short, you keep the intent of your Databricks Workflows but gain the reliability and transparency of Airflow, with all the heavy lifting handled by Yeedu.
Phase 1 - Legacy HMS unlock and UC modernization
Break the dependency on the legacy Hive Metastore by converting its metadata tables, grants, and ownership into native Unity Catalog objects. This makes your governance portable outside Databricks and prepares the environment for Databricks notebook migration or larger multi-workload transitions.
Phase 2 - Complete environment inventory
Scan the entire workspace to produce a detailed Unity Catalog inventory of tables, views, functions, volumes, and dependency graphs. The resulting report becomes the blueprint for migrating Databricks jobs, enabling quick lookups, lineage analysis, and permission validation.
Using this unified inventory and analysis, teams can validate lineage, permissions, and dependencies confidently ensuring safer Databricks notebooks and jobs migration across large, multi-team environments.
Note: Phases 1 and 2 are one-time setup processes that modernize the legacy environment and generate reliable migration blueprints.
Phase 3 - Workflow migration and operational readiness
Use the blueprint to analyze existing jobs and notebooks, update them for the new UC structure, and generate orchestration assets such as Airflow DAGs. Validate safely with dry runs, then promote to production with confidence.
If new pipelines or workflows are added later, simply re-run this phase to migrate the additional assets to Yeedu.
Validate in days, not months
You don’t need a massive migration project to see results.
Start with a single pipeline that currently suffers from slow performance or SLA breaches. Connect it to Yeedu, run it using the Turbo Engine, and measure runtime stability, error rates, and cost improvements. Once validated, expand the same playbook across other workloads.
Yeedu is a cloud cost optimization solution built for data teams that want Databricks-level governance and performance with greater flexibility, cost control, and openness. It’s ideal for organizations seeking to modernize their Spark infrastructure using a no code data migration path, without giving up years of investment in code, catalog, and governance.
Visit docs.yeedu.io to explore more about Yeedu features.



