
Cloud platforms make compute scaling easy, but storage performance often becomes the limiting factor in distributed environments. Workloads such as analytics pipelines, machine learning training, databases, and streaming services generate diverse disk I/O patterns. When cluster storage is not aligned with these patterns, job execution slows, latency increases, and compute resources remain underutilized creating a classic disk bottleneck in distributed systems.
Yeedu addresses this challenge through customized disk configuration, enabling users to attach cloud-native disks to clusters with precisely defined size, IOPS, and throughput directly from a unified interface, without manual cloud provisioning. This approach enables effective cloud disk performance optimization while keeping infrastructure management simple.
Disk configuration becomes essential when workload performance is limited by storage I/O rather than compute. Below are common real-world situations where default cluster disks are unable to meet workload demands.
A data engineering team runs a Spark ETL pipeline processing terabytes of data daily. The cluster scales compute nodes successfully, but job runtimes remain high. Monitoring shows CPU cores waiting on disk operations. Default general-purpose disks cannot deliver the throughput required for shuffle and spill activity. Increasing compute does not help storage performance becomes the limiting factor, requiring targeted Spark disk performance tuning instead of additional cores.
A streaming platform ingests millions of events per minute using Kafka and Spark Structured Streaming. During peak traffic, message processing falls behind, and consumer offsets lag. The root cause is insufficient sustained disk throughput for continuous writes, highlighting the need for better cloud storage performance control at the infrastructure layer.
A production database supporting application traffic experiences unpredictable query latency under high concurrent load. Investigation shows that default disks cannot provide consistent IOPS for random read/write operations, causing request delays.
A GPU-based training cluster shows low GPU utilization. Training jobs frequently wait for data loading from disk. The bottleneck is, insufficient disk throughput to stream large datasets fast enough to keep GPUs busy another example of a disk bottleneck in distributed systems impacting expensive compute resources.
Analytics jobs performing global sort and join operations generate heavy shuffle and spill data. Slow intermediate disk storage increases stage execution time and delays pipeline completion, reinforcing the importance of proactive cloud disk performance optimization.
In all these cases, scaling compute resources does not resolve the issue. The only effective solution is to configure storage performance to match workload I/O demands. This is where custom disk configuration becomes critical.
Improving disk performance in typical cloud environments requires:
This workflow introduces operational overhead and demands infrastructure expertise, slowing down teams focused on application development and data engineering. Achieving proper cloud storage performance control often becomes an infrastructure-heavy exercise rather than an application-focused optimization.
Yeedu eliminates manual storage operations through a dedicated Disk Configuration panel in the cluster creation flow. Users select:
Yeedu automatically validates the configuration, provisions the disks, and attaches them to cluster nodes. The Spark pipeline in the earlier scenario is re-deployed with high-throughput SSD disks. Shuffle operations accelerate; CPU utilization improves, and job runtime drops significantly delivering measurable Spark disk performance tuning without code changes or manual cloud configuration.
Two metrics define disk performance.
IOPS measures the number of read/write operations per second. It is critical for workloads performing many small or random operations, such as databases and metadata services.
Throughput measures how much data can be transferred per second. It is essential for large sequential operations such as Spark shuffles, ETL pipelines, and dataset streaming.
Different workloads require different IOPS-to-throughput ratios. Yeedu exposes both parameters so users can align disk performance with real workload behavior, enabling precise cloud storage performance control across environments.
Yeedu provides a unified, intuitive UI for disk configuration. Users can configure storage performance directly within the cluster setup workflow, with validation of allowed ranges. No cloud-specific knowledge or manual disk allocation is required.
This delivers a consistent, self-service experience across AWS, GCP, and Azure environments, simplifying cloud disk performance optimization in multi-cloud architectures.
Yeedu integrates directly with major cloud storage services.
GCP cloud customized disk configuration in cluster:
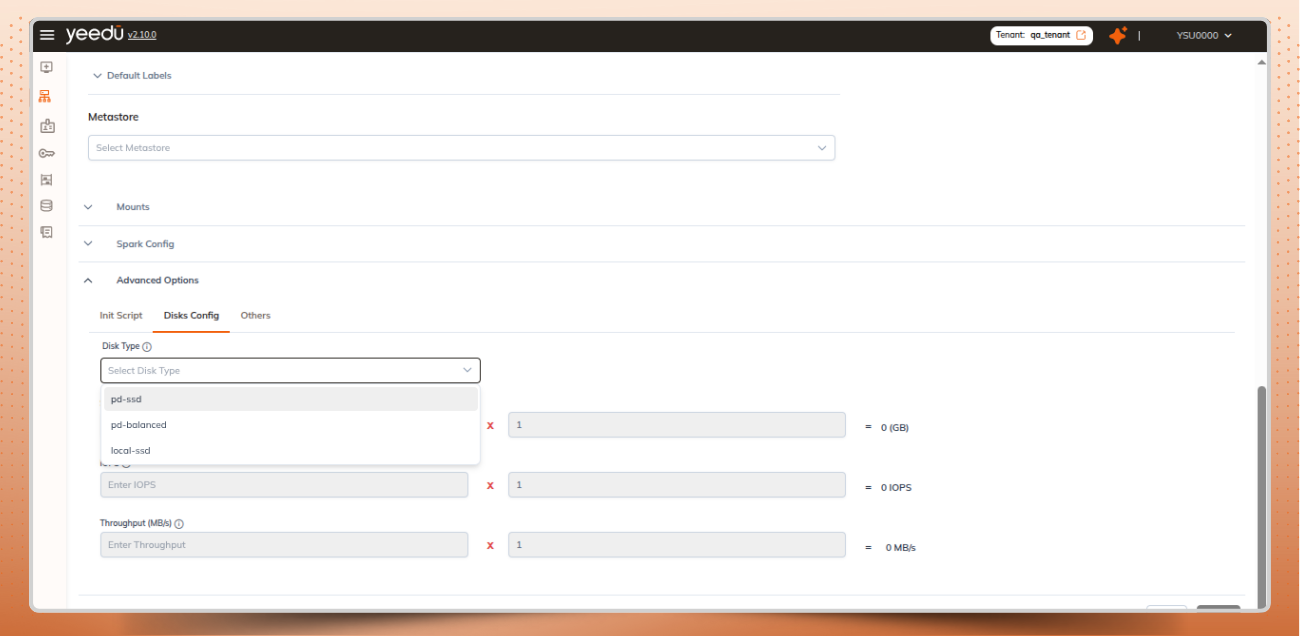
GCP disk configuration options on the cluster page for custom disks
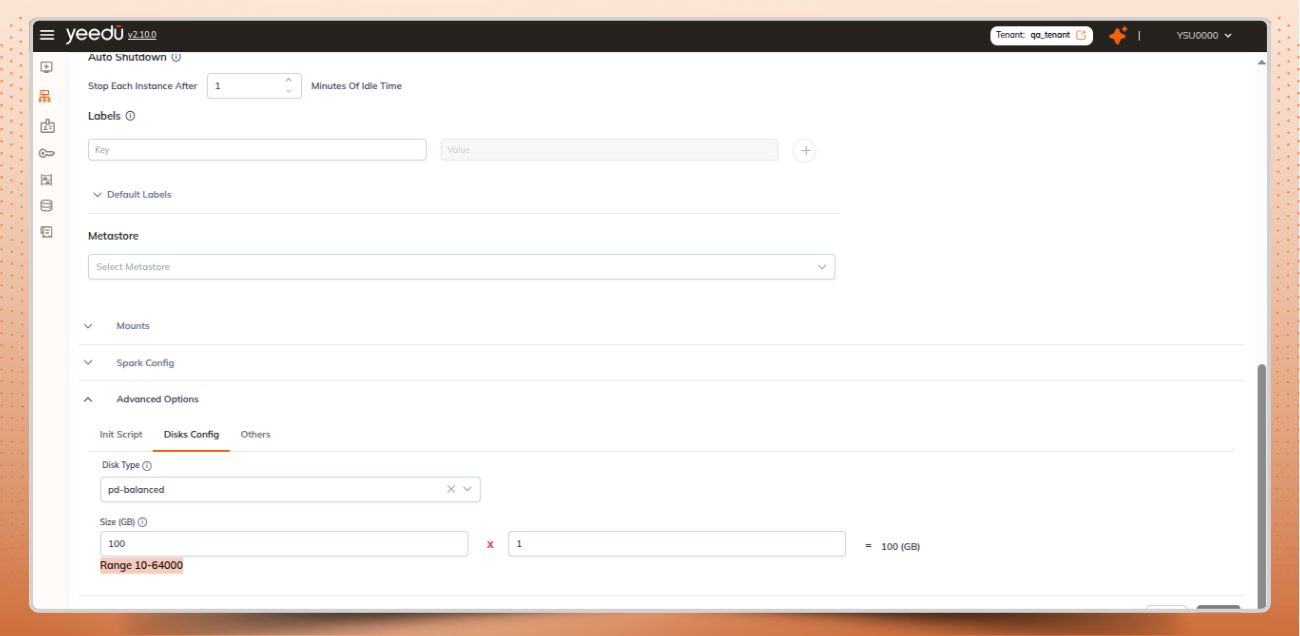
Set disk size, IOPS, and throughput within the allowed ranges and see the total values calculated automatically.
AWS cloud customized disk configuration in cluster:
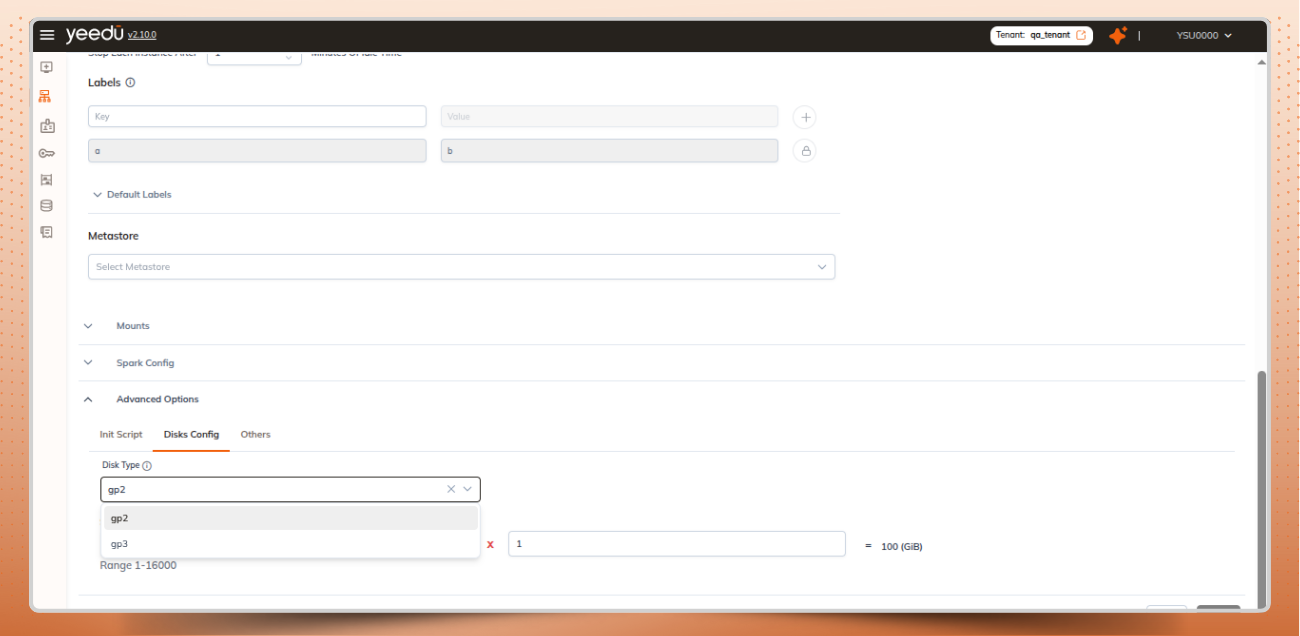
AWS disk configuration options on the cluster page for custom disks
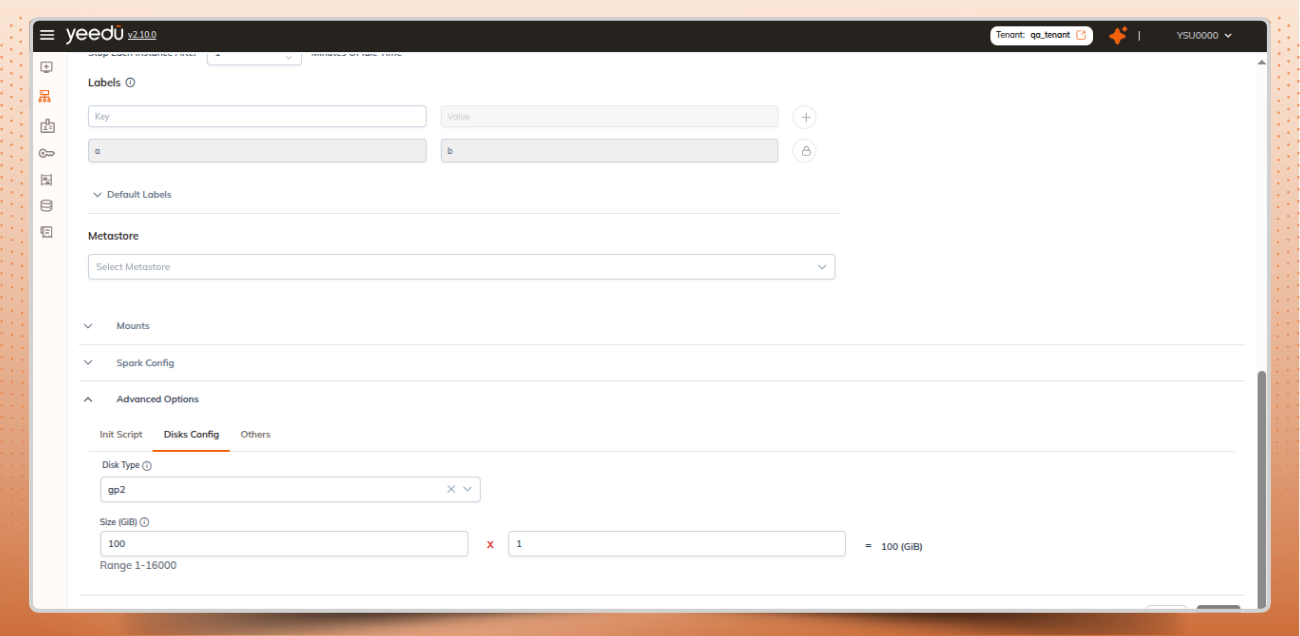
Set disk size, IOPS, and throughput within the allowed ranges and see the total values calculated automatically.
AZURE cloud customised disk configuration in cluster:
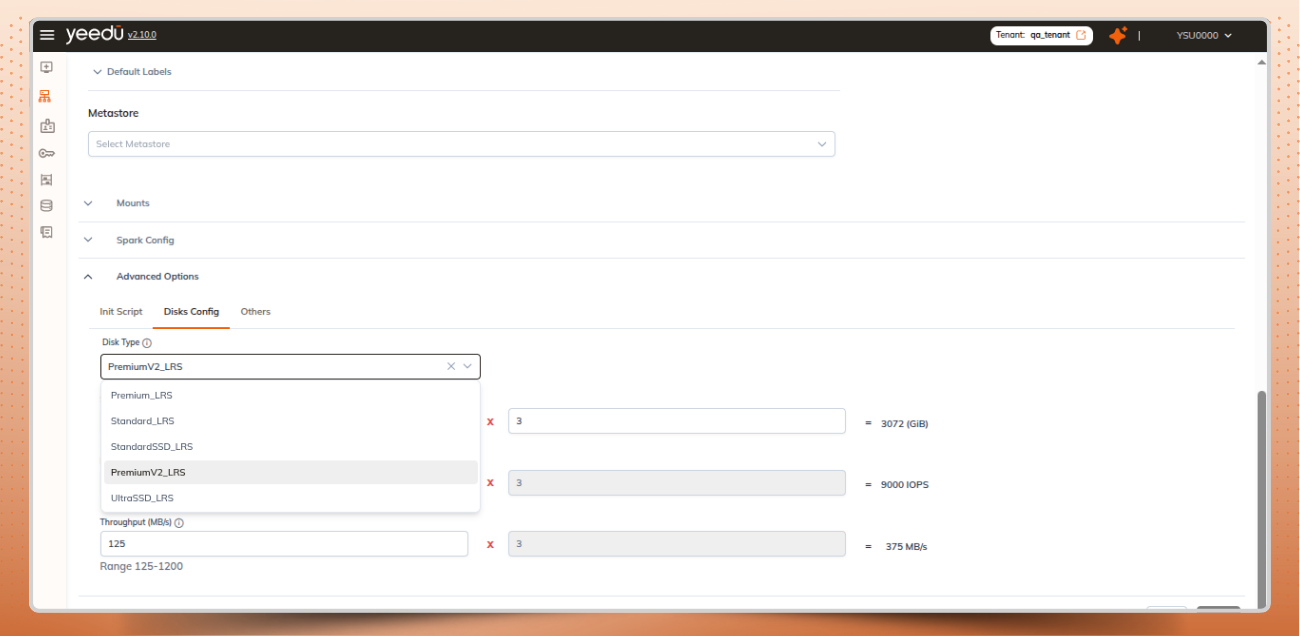
AZURE disk configuration options on the cluster page for custom disks
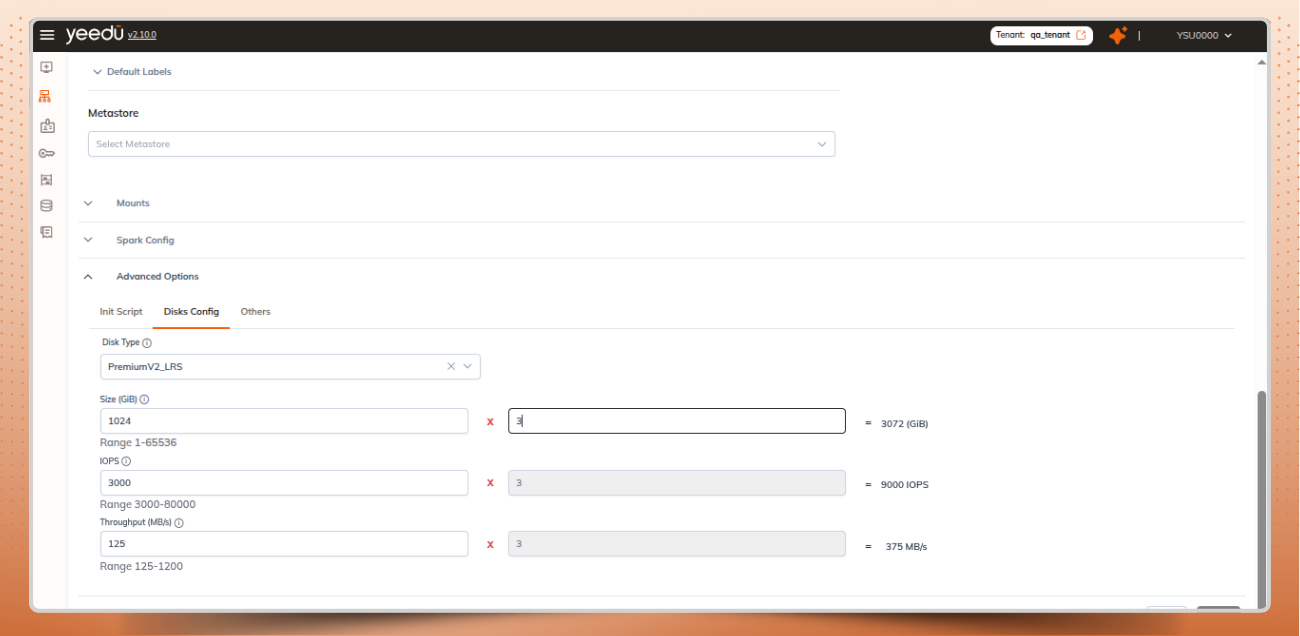
Set disk size, IOPS, and throughput within the allowed ranges and see the total values calculated automatically.
Each disk type follows provider-defined limits for size, IOPS, and throughput. Yeedu enforces these constraints automatically to ensure valid configurations reducing risk while maintaining full cloud storage performance control.
Different workloads stress storage in different ways. Yeedu enables users to choose disk configurations based on workload behavior rather than infrastructure complexity.
This workload-driven approach ensures storage performance is aligned with application needs, avoiding both under-provisioning and unnecessary over-provisioning.
Disk I/O performance is often the hidden constraint in distributed computing. When workloads outgrow default storage capabilities, disk configuration becomes essential. Yeedu transforms this process into a simple, controlled configuration step providing cloud-native disk selection, tunable IOPS and throughput, and fully automated provisioning through a unified UI.
The result is faster workloads, predictable performance, and optimized cloud spending achieved through structured custom disk configuration, targeted Spark disk performance tuning, and precise cloud storage performance control without manual infrastructure operations.



