

Managing dependent Spark workloads across cloud environments shouldn’t feel brittle. Data engineering teams running pipelines on AWS, Azure, and GCP often run into the same set of issues: jobs fail without clear visibility, task dependencies break unexpectedly, and observability gets scattered across multiple cloud consoles. These challenges are common when spark job orchestration using Airflow is implemented without a unified execution layer.
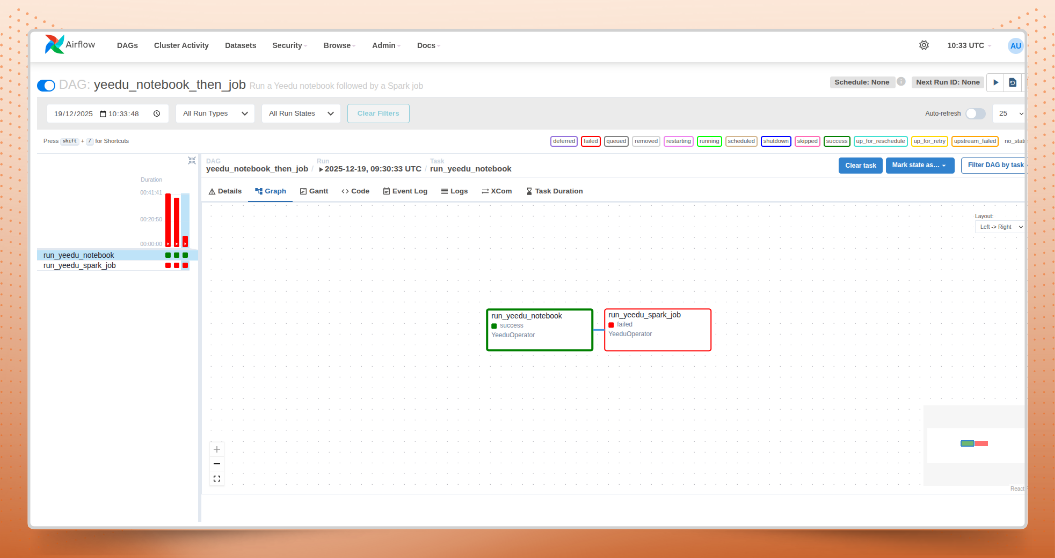
The open-source Yeedu Airflow Operator addresses this by letting you submit Spark jobs and notebooks directly from Airflow DAGs, monitor execution, and access logs in one place ensuring downstream tasks only run after upstream work completes successfully. This enables Spark orchestration with Airflow that is deterministic, observable, and production-ready.
The Yeedu Airflow Operator integrates directly into Airflow to simplify how jobs and notebooks are submitted to Yeedu. From within a DAG, you can trigger workloads, track their execution in real time, and handle outcomes consistently whether a task succeeds or fails. In practice, this functions as a next-generation Airflow Spark operator, purpose-built for modern, multi-cloud Spark workloads.
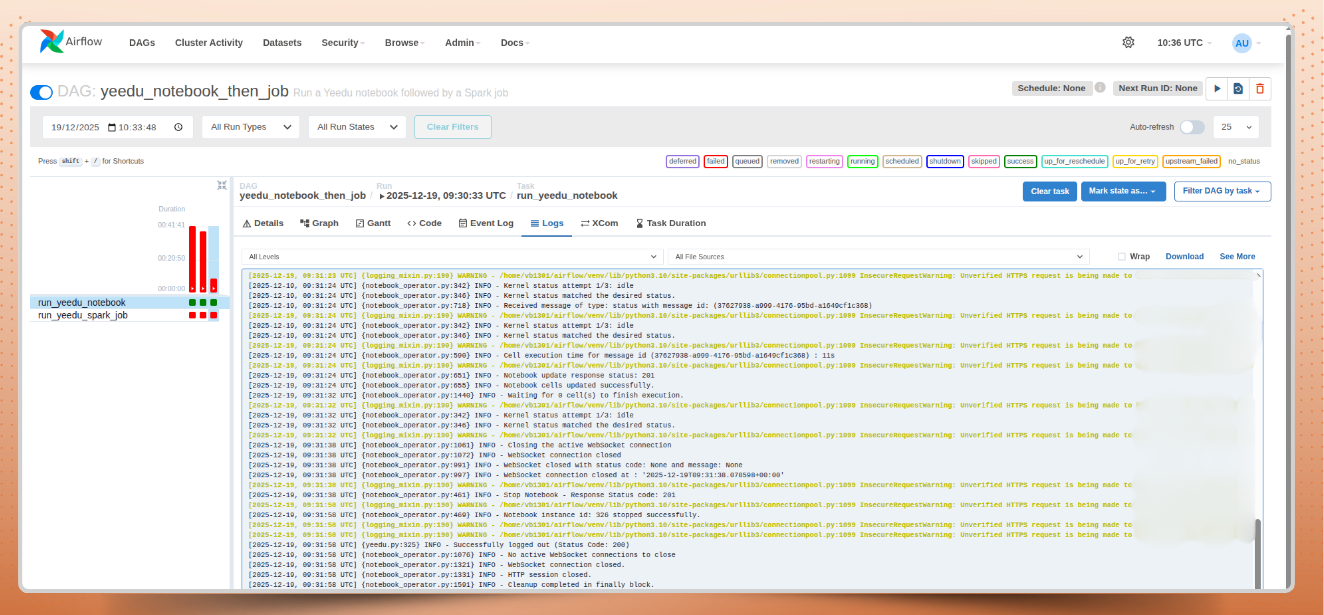
Execution logs for Yeedu jobs and notebooks remain accessible through the Airflow UI, keeping orchestration and Spark job monitoring centralized instead of fragmented across tools.
Airflow’s DAG semantics enforce strict upstream-to-downstream execution. Tasks only begin after dependencies complete successfully, helping teams avoid partial runs, inconsistent datasets, and pipeline failures propagating downstream key requirements for reliable spark job orchestration using Airflow at scale.
Installing the operator is straightforward:
pip3 install airflow-yeedu-operator Once installed, the YeeduOperator becomes available inside your DAGs, enabling you to trigger and monitor both jobs and notebooks from Airflow itself. Execution logs are visible directly in the Airflow interface, strengthening Spark job monitoring without introducing additional observability tools.
The Yeedu Airflow Operator (v2.9.1) is compatible with Airflow 3.x, making it easy to integrate into modern Airflow deployments that rely on Spark orchestration with Airflow.
At runtime, the operator handles:
One of the most powerful capabilities is orchestrating workloads across multiple cloud providers within a single DAG. Each YeeduOperator task can point to a different Yeedu job or notebook, and each job selects its own cluster. These clusters are created per cloud environment whether AWS, Azure, or GCP enabling true multi-cloud orchestration from a single workflow.
This architecture allows you to fan out processing steps to the optimal cloud and cluster configuration for each specific task, then converge the results downstream without breaking DAG semantics.
For example: Run data ingestion on AWS where your raw data resides, perform heavy transformations on GCP for competitive compute pricing, and load results into Azure where your data warehouse lives all orchestrated seamlessly through multi-cloud Spark job orchestration using Airflow.
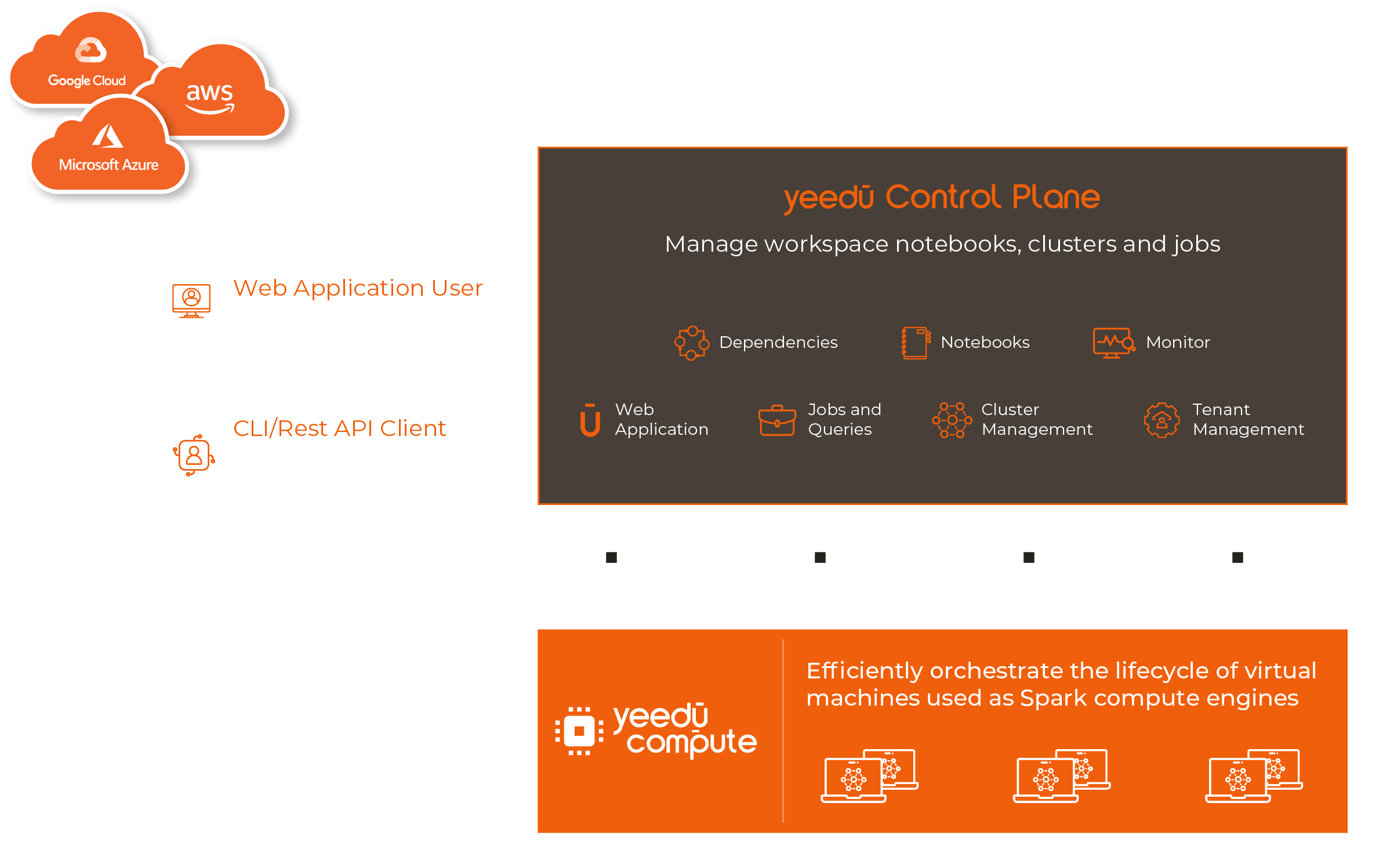
Yeedu orchestrates Spark across AWS, Azure, and GCP from a single control plane. This unified approach is foundational to enabling reliable multi-cloud orchestration without introducing operational sprawl.
The Yeedu Control Plane serves as the platform's backbone, managing all backend services essential for its operation. Configuration of all clusters is handled within the Yeedu Control Plane, with the capability to span across various cloud providers.
The platform abstracts away the complexity of managing Spark clusters across different cloud providers. Yeedu provides a unified interface for job submission, cluster management, and Spark job monitoring, tightly integrated with Airflow.
All Yeedu components are deployed within the customer's Virtual Private Cloud (VPC), ensuring heightened security and data governance.
Cost management is critical for organizations running large-scale data workloads. Yeedu addresses this with intelligent resource management designed specifically for Spark cost optimization:
These features work together seamlessly. Clusters scale up when workloads demand more resources and scale down gracefully as jobs complete, delivering consistent Spark cost optimization without manual tuning.
Airflow DAG semantics provide robust enforcement of upstream-to-downstream task ordering. This ensures predictable, deterministic pipeline execution enabling true multi-cloud orchestration from a single workflow, where each task waits for its dependencies to complete successfully before starting
Trigger runs, watch execution status, and read Spark logs all from within the familiar Airflow UI. Centralized Spark job monitoring eliminates context-switching across cloud consoles. No more context-switching or hunting through distributed logging systems to debug issues. This centralized visibility dramatically reduces the operational overhead of managing complex data pipelines.
Yeedu is built to cut Spark compute costs significantly while maintaining workload compatibility. The platform has helped enterprises achieve industry-leading Spark cost optimization, cutting costs by an average of 60% while delivering 4–10× performance improvements.
Yeedu is a re-architected, high-performance Spark engine that runs the same workloads at a fraction of the cost. Your existing Spark jobs run on Yeedu without modification. The platform's optimizations happen at the execution layer, transparently improving performance and reducing costs.
When you combine Yeedu with Airflow orchestration, data engineering teams can:
Engineers can spend less time managing infrastructure and more time building data products that drive business value.
Traditional multi-cloud Spark orchestration is fragile and expensive. Teams waste time context-switching between cloud consoles, debugging silent failures, and managing over-provisioned infrastructure.
The Yeedu Airflow Operator changes that. By combining Airflow's proven DAG-based orchestration with Yeedu's cost-optimized Spark execution layer, organizations can build reliable, efficient data pipelines that leverage the best of what each cloud provider offer.
Ready to orchestrate your Spark workloads smarter? Install the Yeedu Airflow Operator and discover how easy it is to build reliable, cost-effective data pipelines across AWS, Azure, and GCP.



